Last week, I was assigned an interesting task at work to implement semantic search in our API pipeline so that our LLM could answer customer queries more accurately and in real-time. I had a rough idea of how semantic search worked shoutout to my ML professor, that class finally paid off, but I didn't really know how to get started with implementing it. Here's how I did it.
TL;DR
Semantic search focuses on matching meaning rather than just keywords. I implemented it using OpenAI's embeddings model, optimized the vector dimensions for better performance, created a fast indexing layer, and updated our query flow to use semantic similarity instead of parameter-based matching. Result was a smarter search with faster, more relevant responses improving performance and accuracy of the LLM responses.
What is semantic search and how is it different?
 Traditional search systems rely on lexical matching where they look for exact or partial keyword matches in the data. If a user searches for “laptop”, the system will only return results that contain the exact word “laptop.” It doesn't understand that “chromebook” or “MacBook” might mean the same thing in context.
Traditional search systems rely on lexical matching where they look for exact or partial keyword matches in the data. If a user searches for “laptop”, the system will only return results that contain the exact word “laptop.” It doesn't understand that “chromebook” or “MacBook” might mean the same thing in context.
Semantic search works differently. Instead of just matching strings, it tries to match meanings.
So even if the user doesn't use the exact keyword in the dataset, the search engine can still find conceptually relevant results. This is what makes semantic search more intelligent and useful than plain keyword-based search.
How to implement semantic search?
1. Choose a model and generate embeddings
- The first step is to convert your data into embeddings, which are high-dimensional vector representations that encode semantic meaning.
- I used OpenAI's
text-embedding-3-largemodel. You send it text, and it gives you a vector. My initial output was a 3075 dimensional vector. That's a lot, which is great for accuracy, but not so great for performance so I trimmed it down to 2000 dimensions (why? more on that next). - You don't need multimodal embeddings unless you're dealing with images or videos. For me text-only works fine.
2. Choose the right dimensionality
- More dimensions = better semantics = better results... but unless you have a supercomputer, it also means higher compute and slower queries.
- Larger vectors slow down queries and add pressure on your database, especially at scale. This is why it's important to experiment and find the right balance. For me, trimming the dimensions from 3,075 to 2,000 gave a good trade-off between speed and relevance.
- The right number will depend on your specific use case, data, and performance requirements.
3. Index Your Embeddings
- Once your data is vectorized and stored, you need an indexing strategy that supports fast similarity searches. Without an index, every query would require scanning the entire dataset, which is slow and inefficient.
- This is where approximate nearest neighbor (ANN) search comes in. ANN indexing sacrifices a small amount of recall to dramatically improve performance, making it a practical choice for most production setups.
- Here are the three indexing methods I considered:
- IVFFlat
- This method uses k-means clustering to partition your data into lists. During a search, only a subset of those lists are scanned. You can control how many lists to probe, which allows you to adjust the balance between speed and accuracy.
- This method requires training and works well when you want more control over performance tuning.
- HNSW
- The HNSW algorithm builds a multi-layered graph of vectors. It starts the search at the top layer and narrows down as it gets closer to the best matches.
- HNSW usually has a better speed-to-recall tradeoff than IVFFlat and does not require training. You can create an HNSW index even if your table is currently empty.
- DiskANN
- DiskANN is built for scale. It provides high recall and low latency even with billions of records. While it requires more time and memory to build, it is a solid choice for high-throughput, low-latency scenarios.
- IVFFlat
4. Update the Query Flow
- In a typical search setup, you parse the user query, extract parameters, and generate a structured SQL or NoSQL query. With semantic search, the flow changes.
- You first generate an embedding for the user's natural language query. Then, you compare this vector with the stored embeddings in your database.
- There are a few options for calculating vector similarity:
- I used cosine similarity because it worked well for my text-based use case. After comparing, you return the top n most similar results. This flow allows users to ask questions in plain language, and still get highly relevant responses.
Incase you are wondering if it's worth the effort, here are some performance benchmarks I ran:
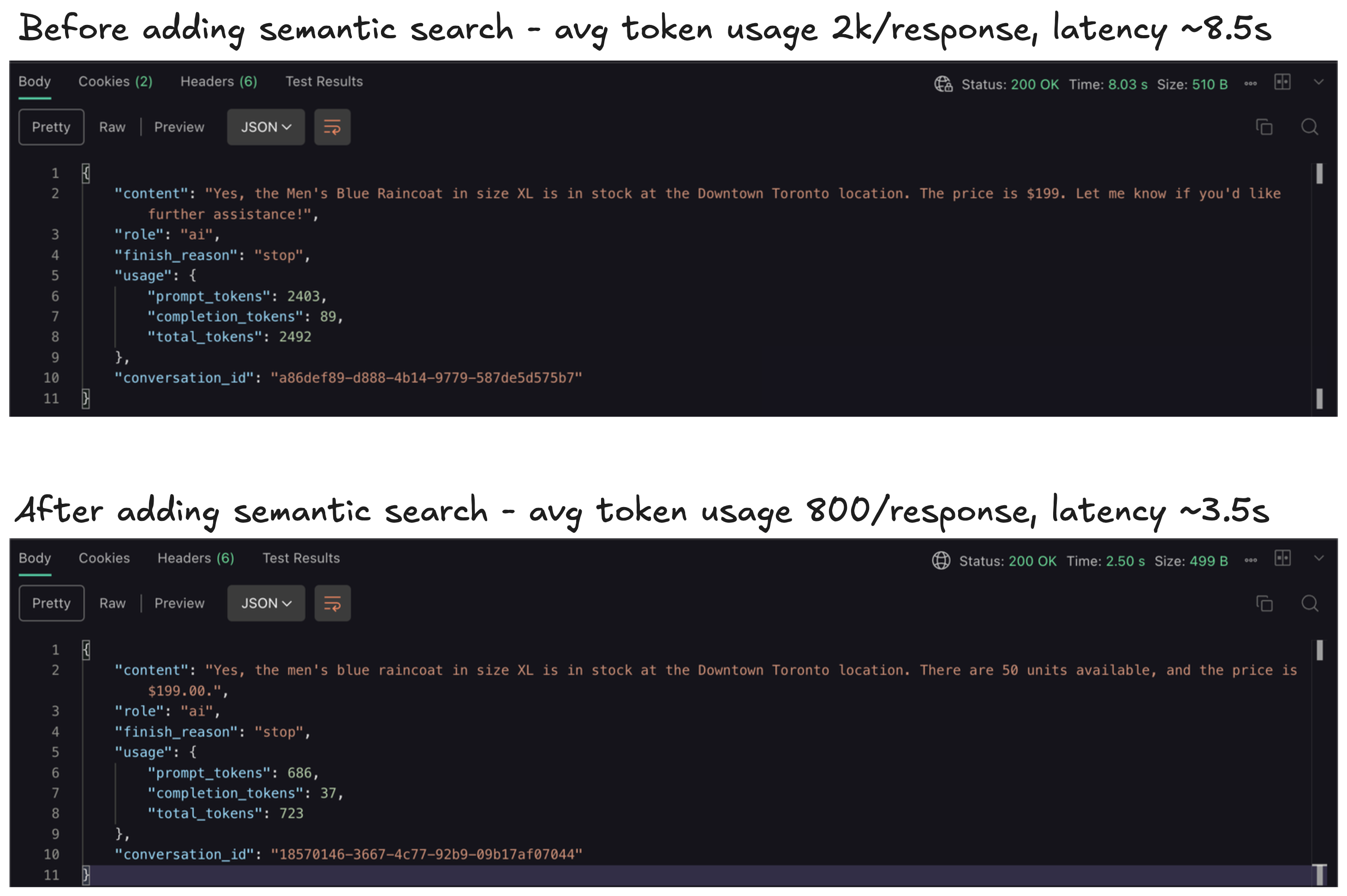
Final Thoughts
- Semantic Search + LLMs = 🔥
- Semantic search is a perfect complement to LLMs. Instead of passing all your data to the model, you can first use semantic search to narrow it down to only the most relevant parts.
- This leads to faster responses, lower token usage, and better accuracy. It also reduces hallucinations because the model receives focused, relevant information rather than having to reason over a massive context.
- In short, semantic search filters and the LLM interprets, creating much better user experiences together.
